
2024年全国高考结束后,国内外众多AI大模型随之上阵,在考场外参加了一场“高考”。6月24日,极客公园高考新课标Ⅰ卷全科目大模型评测报告出炉,成绩单让广大网友很感兴趣。
据了解,本次“大模型考生”包括GPT-4o(OpenAI)、豆包(字节跳动)、文心4.0(百度)、百小应(百川智能)、通义千问2.5(阿里巴巴)、Kimi智能助手(月之暗面)、元宝(腾讯)、智谱清言(智谱AI)以及海螺AI(MiniMax)等。使用的考卷,是覆盖地域广泛的“新课标Ⅰ卷”,与河南省考生所用的考卷相同。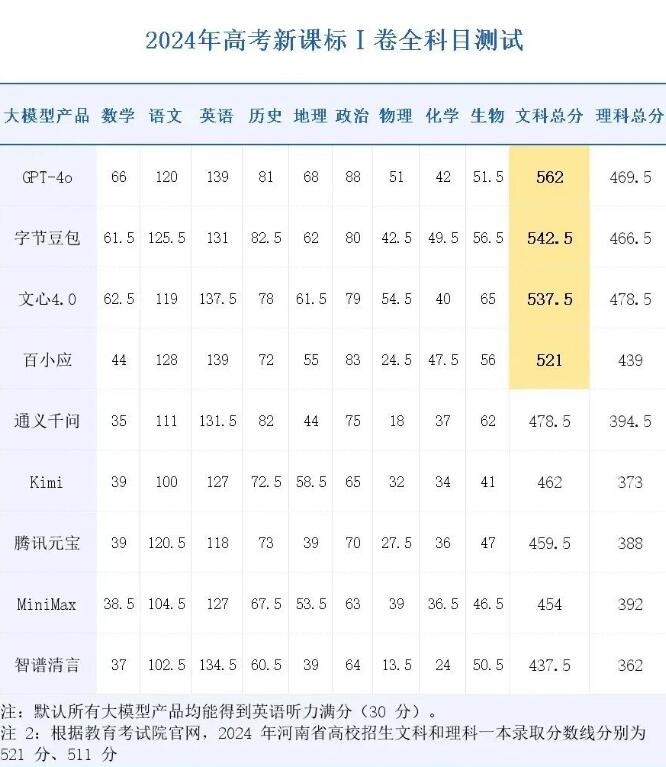
从考试成绩来看,在文科方面,GPT-4o以562分位列榜首,国产大模型豆包表现优异,斩获542.5分的高分,成功超过河南文科一本线20多分。据悉,2024年河南文科本科一批录取分数线为521分,豆包、文心4.0、百小应三款国产AI大模型成功“冲上一本线”。
AI大模型“集体参加2024年高考”,成绩单揭晓,文科成绩优异,理科普遍欠佳
真实考题+名师阅卷文科表现出色,理科成绩欠佳
据了解,本次大模型“高考”,语文作文的阅卷人是北京市级骨干教师、怀柔区语文学科带头人夏老师。夏老师多次参与全国高考语文阅卷,经验颇为丰富。记者综合网络资料发现,在文科考试中,大模型们的表现普遍比较出色,特别是在语言类科目上,展现出了一定的逻辑与语言组织能力。然而在写作方面,尽管大模型的文章结构清晰、语言通顺,但普遍存在理性有余而感性不足的情况,缺乏感情色彩与感染力。
理科方面,大模型们的成绩则普遍欠佳,多数大模型的理科总分在400分以下,与河南理科511分的一本线存在差距。
理科普遍不及格,大模型更像文科生
资料显示,在由历史、地理、政治组成的新课标“文综”考卷评测中,GPT-4o获得237分,平均分79分,优于多数真实考生。
国产大模型产品中,豆包的文综成绩最高,为224.5分。历史科目最高分82.5分,豆包摘得;政治科目最高分88分,GPT-4o摘得;地理科目最高分68分,GPT-4o摘得。
理科考试中,9款大模型产品里,数学考试只有GPT-4o、文心一言4.0和豆包获得60分以上的成绩,但面对满分150分的试卷,均未及格。在重点考查实验探究能力的化学和物理试卷中,各模型的平均分分别只有34分(满分100分)和39分(满分110分)。
尽管在理科考试中,各家大模型都有可圈可点之处,例如“豆包”大模型在求导题目和三角函数题上表现较好,展现出了一定的解题能力,但整体而言,在本次“高考”中数理科目全线不及格,大模型的理科最好成绩还无法进入真实考生的前30%。如何让大模型“文理兼修”,像人类一样思考和解决问题,大模型或许还有很长的路要走。
国产AI技术能力显著进步,挑战依然巨大
从这次“高考”结果来看,大模型在文科领域展现出了一定的优势,尤其在语言处理和知识记忆方面表现突出。河南高考分数段统计数据显示,GPT-4o的562分在文科考生中排名8811名,相当于真实考生的前2.45%,国产大模型“豆包”位列约4.27%的位置。在过去一年多的时间里,国产AI技术能力取得了显著进步。
理科领域,面对需要深度逻辑推理和灵活应变的问题时,大模型仍面临巨大挑战。这表明大模型在处理某些特定类型的任务时具备较强能力,但在综合运用知识和解决复杂实际问题方面,与人类的智力水平仍存在差距。
此次通过“高考”检验各家大模型,不仅备受业界及广大网友关注,对于大模型的发展也意义重大。一方面,为评估大模型的学习和知识运用能力提供了全新、客观的标准。同时,也让我们更加清晰地看到了各家大模型的优势和不足。在接下来的一年中,各家大模型将如何进步与发展,值得持续追踪。